Findings
DORA explores early in MAB and converges quickly to the optimal arm.
Arms selected by DORA over a single episode. In the early timesteps the λ policy samples all arms, and as t grows λ increases and the agent shifts to exploiting the optimal arm (red).
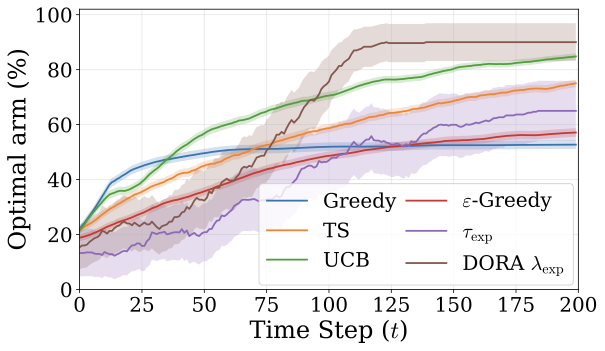
Optimal-arm selection across methods over a horizon of T = 200. DORA explores more in the early stages but selects the optimal arm more often as the episode progresses.
DORA achieves near-optimal performance on Multi-Armed Bandits.
Multi-Armed Bandits (MAB) provide a classical testbed for the exploration–exploitation trade-off. We study the hard instance with K=5 arms, gap Δ=0.2, and horizon T=200. For τ ≤ 1, the model behaves overly greedily, often committing early to a suboptimal arm (suffix failure up to 95%). For τ > 1, increased randomness prevents consistent exploitation. DORA explores effectively in early stages and rapidly converges to the optimal arm, achieving zero Suffix Failure Frequency and approaching the near-optimal UCB baseline.
| Metric | UCB | TS | Greedy | ε-Greedy | τ=0 | τ=0.7 | τ=1 | τ=1.5 | τexp | DORA |
|---|---|---|---|---|---|---|---|---|---|---|
| Mean Avg Reward | 0.531 | 0.512 | 0.506 | 0.490 | 0.410 | 0.410 | 0.401 | 0.440 | 0.433 | 0.514 |
| SuffFailFreq(T/2) | 0.02 | 0.00 | 0.42 | 0.30 | 0.90 | 0.90 | 0.95 | 0.25 | 0.10 | 0.00 |
| Best Arm Fraction | 0.66 | 0.57 | 0.53 | 0.455 | 0.10 | 0.10 | 0.04 | 0.301 | 0.434 | 0.585 |
| Cumulative Regret | 13.68 | 17.16 | 18.90 | 21.80 | 36.00 | 36.00 | 38.39 | 28.45 | 24.41 | 16.61 |
Table 1. Performance on the hard MAB instance (Llama-3.1 8B).
DORA improves overall task success on TALES.
DORA visits over 2× more unique states in TextWorld and ScienceWorld, enabling discovery of hidden objects and task-relevant signals. By enabling agents to discover new information and avoid repetitive loops, DORA leads to consistent performance gains across all TALES environments, including measurable progress in AlfWorld where feedback is sparse and unhelpful.
| Model | Setting | TextWorld | TW Express | AlfWorld | ScienceWorld | Jericho |
|---|---|---|---|---|---|---|
| Qwen-2.5 7B | Zero-shot | 29.20±1.92 | 48.93±1.69 | 0.00±0.00 | 13.49±0.12 | 0.66±0.04 |
| Chain of Thought | 24.89±0.91 | 37.44±0.00 | 0.00±0.00 | 9.81±0.18 | 1.58±0.03 | |
| Tree of Thought | 11.39±0.83 | 45.90±0.21 | 0.00±0.00 | 10.10±0.00 | 1.40±0.00 | |
| Prompt Explore | 23.12±1.29 | 47.81±0.00 | 0.00±0.00 | 13.21±0.34 | 1.27±0.04 | |
| DORA (Ours) | 45.40±1.68 | 51.17±3.38 | 2.78±2.78 | 19.01±0.62 | 1.42±0.24 | |
| Llama-3.1 8B | Zero-shot | 40.74±0.67 | 48.29±1.04 | 0.00±0.00 | 15.53±0.50 | 2.21±0.14 |
| Chain of Thought | 37.72±1.16 | 24.72±2.50 | 0.00±0.00 | 7.81±0.87 | 2.22±0.22 | |
| Tree of Thought | 15.06±0.69 | 15.52±0.21 | 0.00±0.00 | 8.64±1.64 | 2.05±0.15 | |
| Prompt Explore | 43.07±0.72 | 52.77±2.08 | 0.00±0.00 | 13.70±0.59 | 1.60±0.21 | |
| DORA (Ours) | 50.15±6.88 | 52.89±3.51 | 2.78±2.78 | 16.85±0.58 | 2.17±0.21 | |
| Mistral Small 22B | Zero-shot | 62.25±1.08 | 31.70±2.08 | 0.00±0.00 | 26.47±0.57 | 1.35±0.03 |
| Chain of Thought | 31.43±2.22 | 25.16±0.28 | 0.00±0.00 | 9.63±0.35 | 1.43±0.13 | |
| Tree of Thought | 32.54±0.83 | 26.40±1.71 | 0.00±0.00 | 10.88±0.85 | 1.27±0.03 | |
| Prompt Explore | 50.60±0.69 | 42.46±0.79 | 0.00±0.00 | 21.48±0.48 | 1.70±0.05 | |
| DORA (Ours) | 74.28±2.99 | 43.12±1.21 | 2.78±2.78 | 32.43±1.15 | 2.92±0.66 |
Table 2. Performance across TALES environments, reported as mean normalised scores ± standard error over 3 runs.
DORA enables loop recovery with 5× to 20× higher rates.
Baseline methods frequently enter loops and rarely recover (below 1%). DORA substantially reduces loops encountered and achieves 5× to 20× higher recovery rates across all TALES environments.
| Method | TextWorld | ScienceWorld | AlfWorld | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Loops | Rec. | % | Loops | Rec. | % | Loops | Rec. | % | |
| Zero-shot | 612 | 3 | 0.5 | 2551 | 9 | 0.35 | 811 | 0 | 0.0 |
| Prompt Explore | 663 | 5 | 0.8 | 2321 | 10 | 0.43 | 721 | 1 | 0.1 |
| CoT | 673 | 24 | 3.6 | 2621 | 6 | 0.23 | 846 | 1 | 0.1 |
| ToT | 783 | 8 | 1.0 | 2801 | 2 | 0.07 | 857 | 0 | 0.0 |
| DORA (Auto) | 185 | 36 | 19.5 | 1234 | 45 | 3.6 | 111 | 12 | 10.8 |
Table 3. Loops encountered, loops recovered, and recovery rate (%) across TALES environments.
DORA covers more states compared to baselines.
DORA visits significantly more unique states per task across all TALES environments, indicating greater coverage and information gathering.
Figure 1. Average number of unique states visited per task across TALES environments.
DORA consistently outperforms all temperature strategies.
| Model | τ=0 | τ=0.3 | τ=0.7 | τ=1 | τ=1.5 | τ=2 | τ-policy | DORA |
|---|---|---|---|---|---|---|---|---|
| Llama-3.1 8B | 39.41 | 34.08 | 30.74 | 14.33 | 0.00 | 0.00 | 0.00 | 44.74 |
| Qwen-2.5 7B | 27.65 | 23.65 | 26.74 | 17.65 | 21.83 | 12.83 | 10.33 | 44.62 |
| Mistral Small 22B | 60.16 | 54.62 | 39.83 | 5.83 | 5.83 | 0.00 | 0.00 | 73.59 |
Table 4. Comparison of τ-sampling strategies against DORA on TextWorld.
α=0.8 yields the best confidence–consistency trade-off.
| (α,β) | (1.0,0.0) | (0.8,0.2) | (0.6,0.4) | (0.4,0.6) | (0.2,0.8) | (0.0,1.0) |
|---|---|---|---|---|---|---|
| Mean Reward | 0.496 | 0.514 | 0.509 | 0.506 | 0.500 | 0.511 |
| SuffFail | 0.05 | 0.00 | 0.05 | 0.05 | 0.05 | 0.00 |
| Best Arm | 0.516 | 0.585 | 0.584 | 0.540 | 0.528 | 0.577 |
| Regret | 19.34 | 16.61 | 16.63 | 18.40 | 18.90 | 16.92 |
Table 5. Effect of the α confidence–consistency weighting on MAB performance.
Auto-Explorer outperforms the λ-scheduler on complex tasks.
| Model | λ-Sched | Auto |
|---|---|---|
| Qwen-2.5 7B | 5.83 | 42.95 |
| Llama-3.1 8B | 21.00 | 41.89 |
| Mistral Small 22B | 9.17 | 69.57 |
Table 6. λ-schedule versus Auto-Explore on TextWorld.
DORA uses more tokens but achieves substantially better outcomes.
DORA Explorer uses ~2× more tokens than Prompt Explore (which uses the fewest), but this additional compute translates into significantly better task performance.
Figure 2. Average token usage per task on TALES TextWorld.